Time Schedule
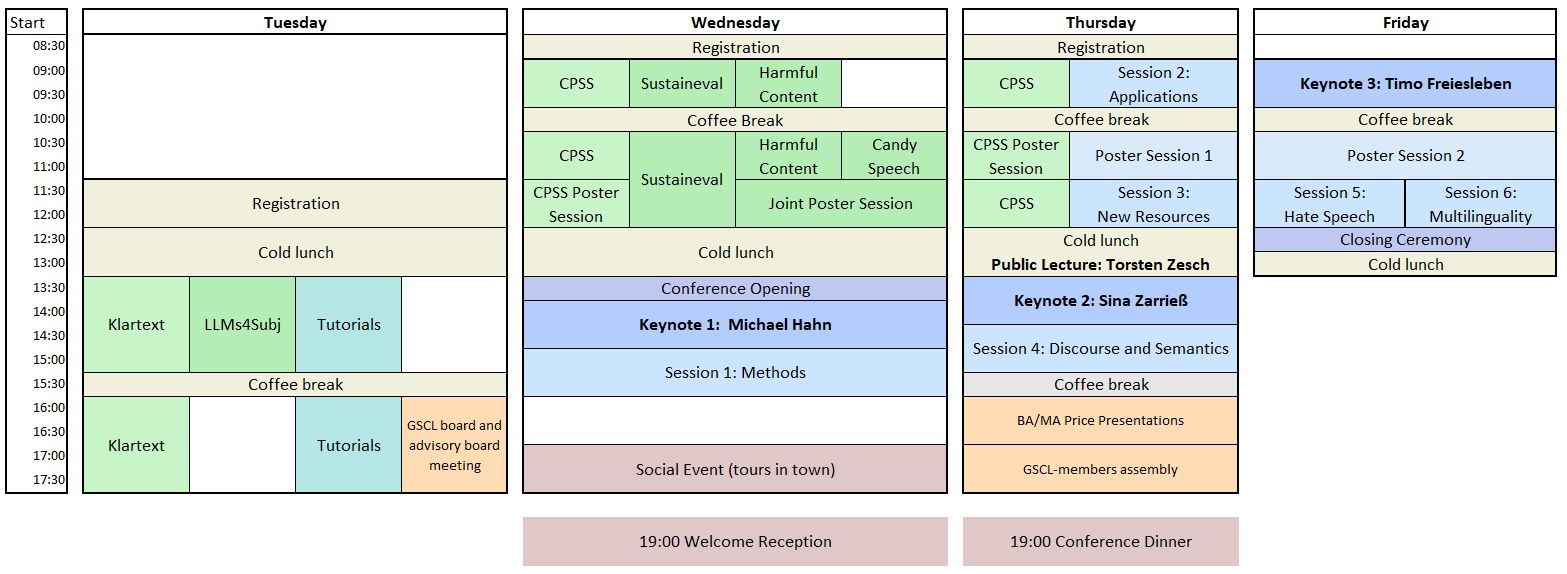
Click on the day to see the detailed day program. Please refer to the program page for details on each session.
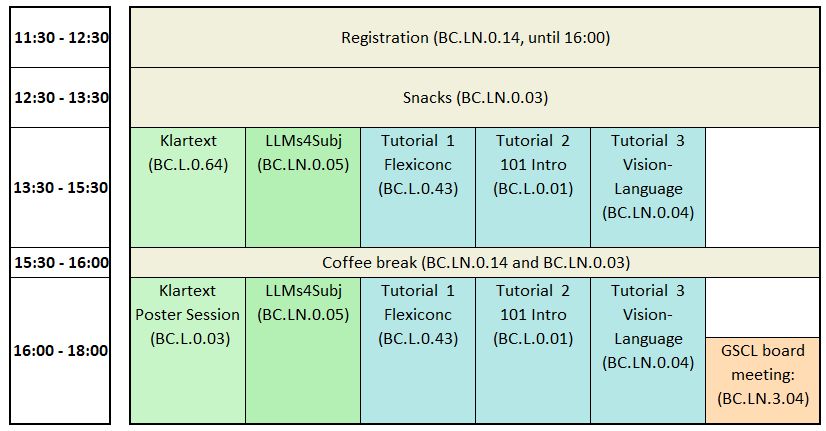
Tuesday, Sept. 9
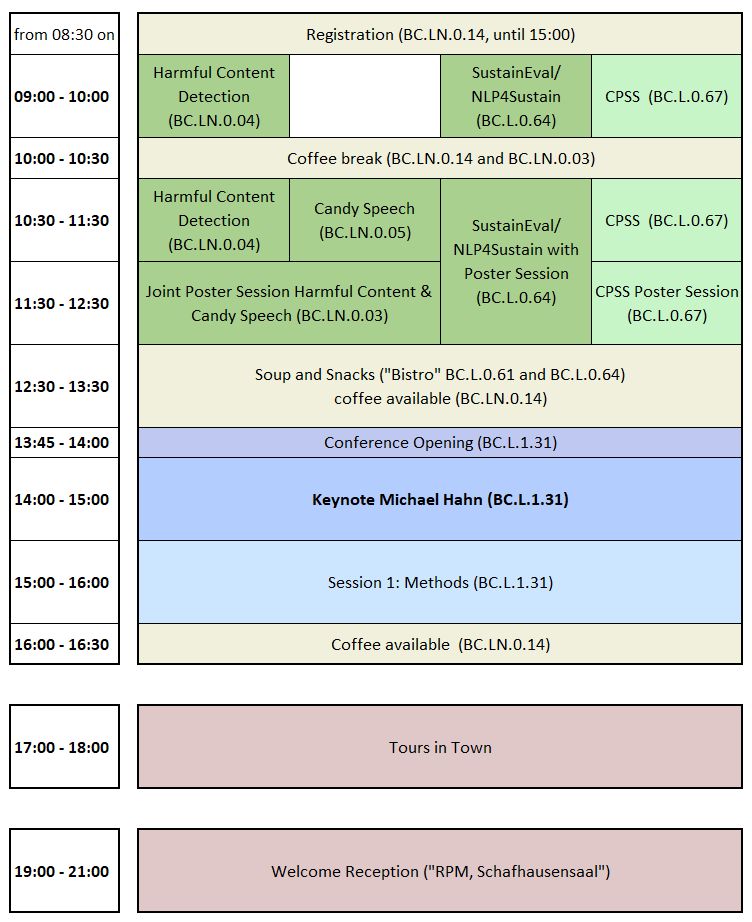
Wednesday, Sept. 10
Thursday, Sept. 11

Friday, Sept. 12

Click on the day to see the detailed day program. Please refer to the program page for details on each session.